The problem with cancellations, and how data science can help
Ultimately, this kind of analysis helps us to adjust our algorithms and user interfaces to improve the service for each and every one of our customers.


Cancellations are problematic for organizations running on-demand transportation. Not only can they mean lost revenue, but cancellations make it difficult to pool rides, resulting in unnecessary driving and longer waiting times for other riders.
In this blog post, we embark on a typical ‘data journey’ to explore when and why riders cancel their bookings. We reveal unexpected cancellation hotspots, develop different cancellation profiles based on rider behaviour, and identify the cancellations that cause us the biggest headaches. We then show how we use machine learning models to predict cancellations in advance, to an accuracy of over 90%. Ultimately, this kind of analysis helps us to adjust our algorithms and user interfaces to improve the service for each and every one of our customers.
The Spare platform churns out data all the time. We rely on data science – a field that blends different mathematical and visualization tools – to uncover hidden patterns from those numbers. Traditionally, ‘data analysts’ have been tasked with describing the data produced and collected by their business, usually in hindsight. However, as datasets and the sophistication of algorithms have grown, a new breed of data scientists can go much further by making predictions based on real information.
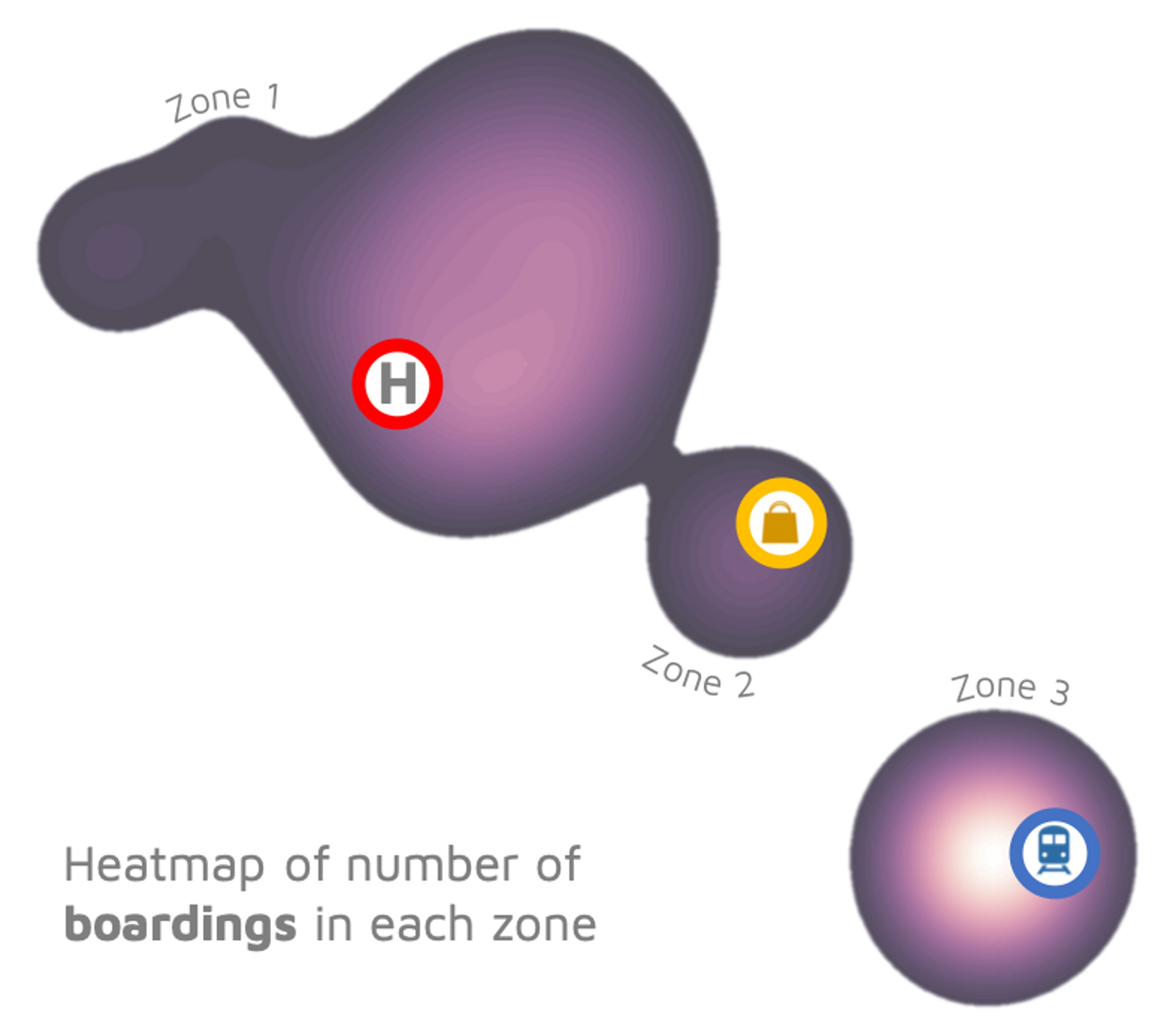
To illustrate our use of data science, we will analyze two months of data from a Spare service, which consists of three distinct zones. In the interests of confidentiality and privacy, we have removed any identifiable information about the service itself, but the patterns we uncover are real!
The root causes of cancellations
A first step in any data science project is to dig into what the data actually look like. We typically use a wide variety of data visualization techniques for this, so we’ll only show a few here. In most examples, we have divided our dataset into trips that were fully completed versus trips that were cancelled.
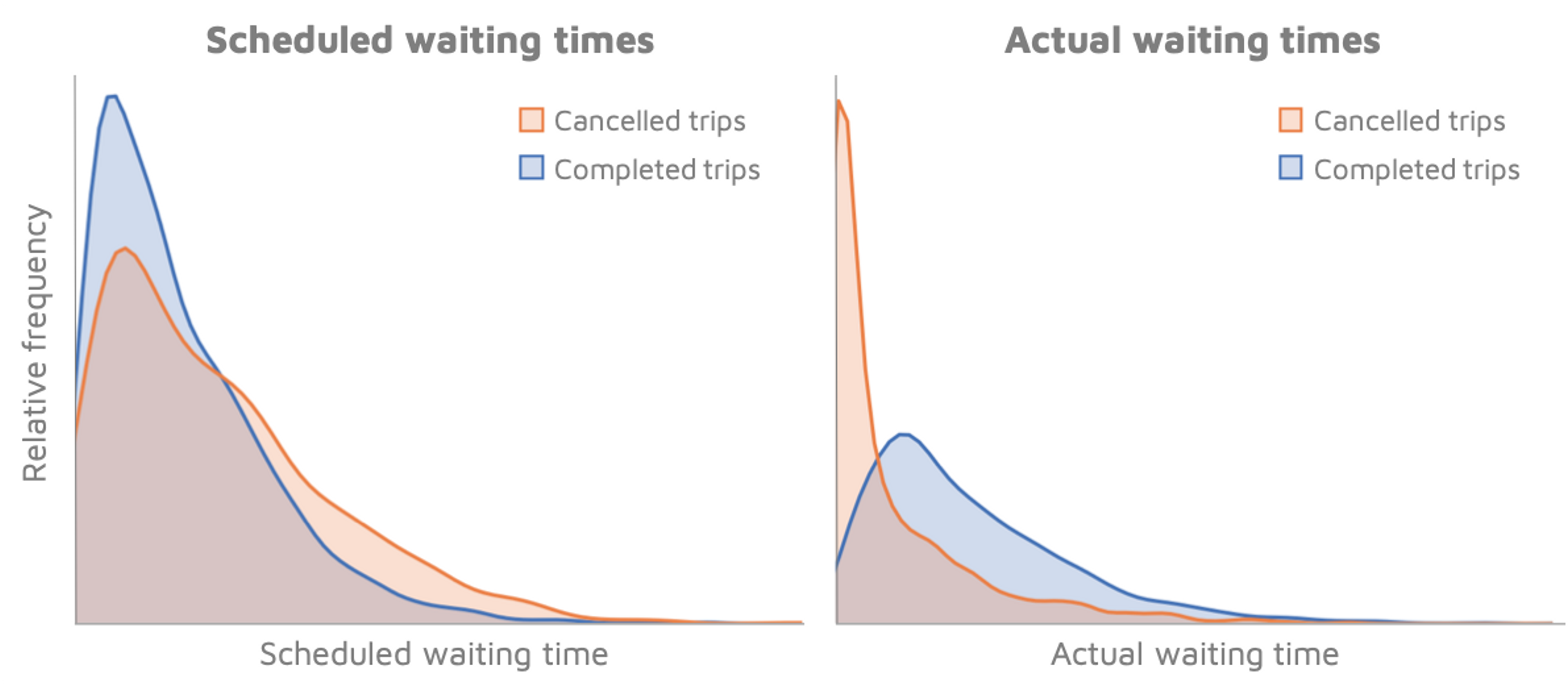
We first plot the raw distribution of the scheduled waiting times (i.e. how long our app tells the rider they will have to wait before they are picked up) and the actual waiting times (i.e. how long they actually waited for). Cancelled trips have proportionally longer scheduled waiting times than completed trips: this suggests that riders who eventually cancel are being put off by the prospect of waiting for longer.
It’s also clear that many riders who cancel do so within a very short period of time. Are these cancellers making erroneous bookings, or gaming the system by rebooking and hoping for shorter waiting times? It’s important to differentiate between the two, because they require different solutions.
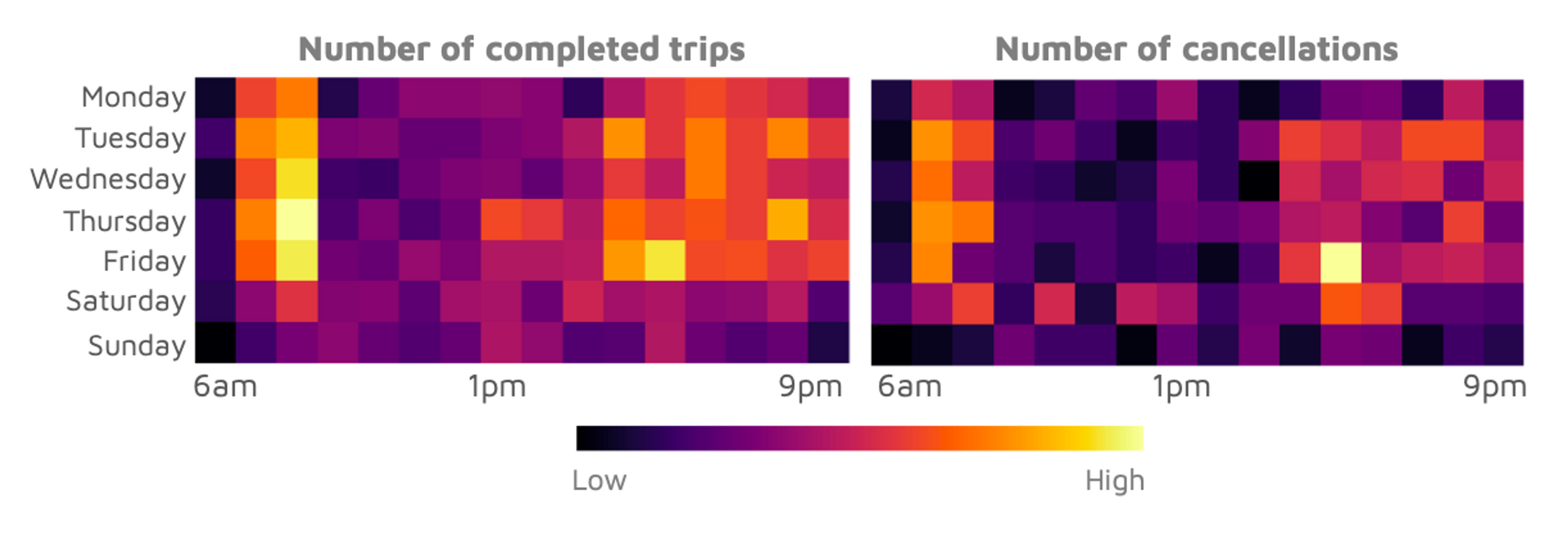
To identify hotspots of cancellations through time, we average our data by weekday and by hour, and combine them in the form of heatmaps. The heatmaps reveal the typical bimodal distribution of a commuter service, with a distinct hotspot in the morning rush hour and a broader one in the evening.
Interestingly, trips and cancellations tend to occur increasingly early in the evening as the week goes on: workers want to get home earlier by Fridays! Cancellations occur surprisingly often on Saturdays, perhaps because weekend shoppers have more flexible schedules, so are willing to cancel and rebook trips if waiting times are too high. These insights can help the transit operator deploy vehicles more optimally at key times.
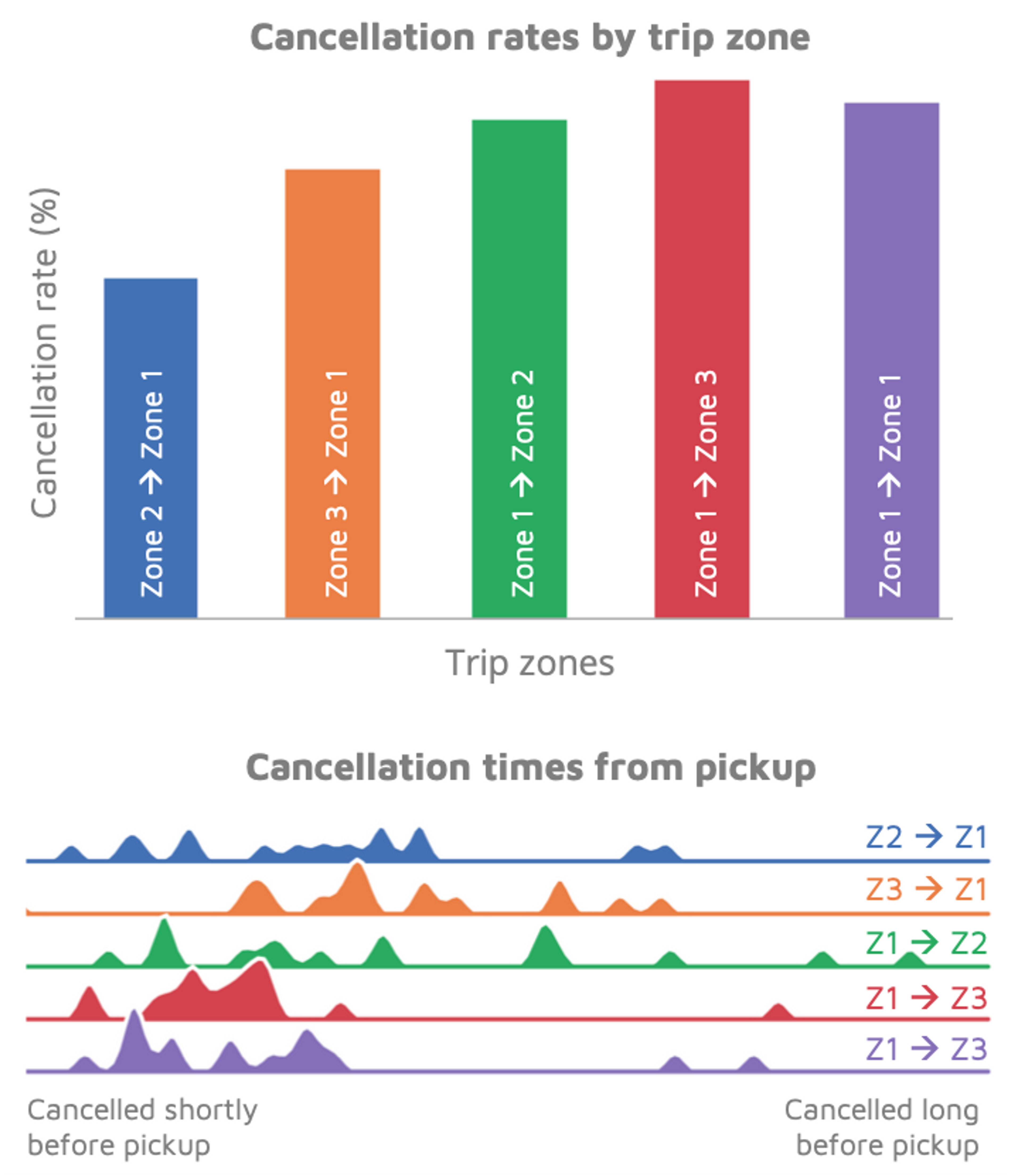
By categorizing trips into the different zones in which they begin and end, we find that cancellation patterns vary across the city. Trips starting in Zone 1 are the most problematic: they have the highest cancellation rates, and cancellations tend to occur a very short time before pickup, complicating things for our routing and pooling algorithms! These problematic trips may be linked to hospital visits, when riders can’t always guess their exact departure time.
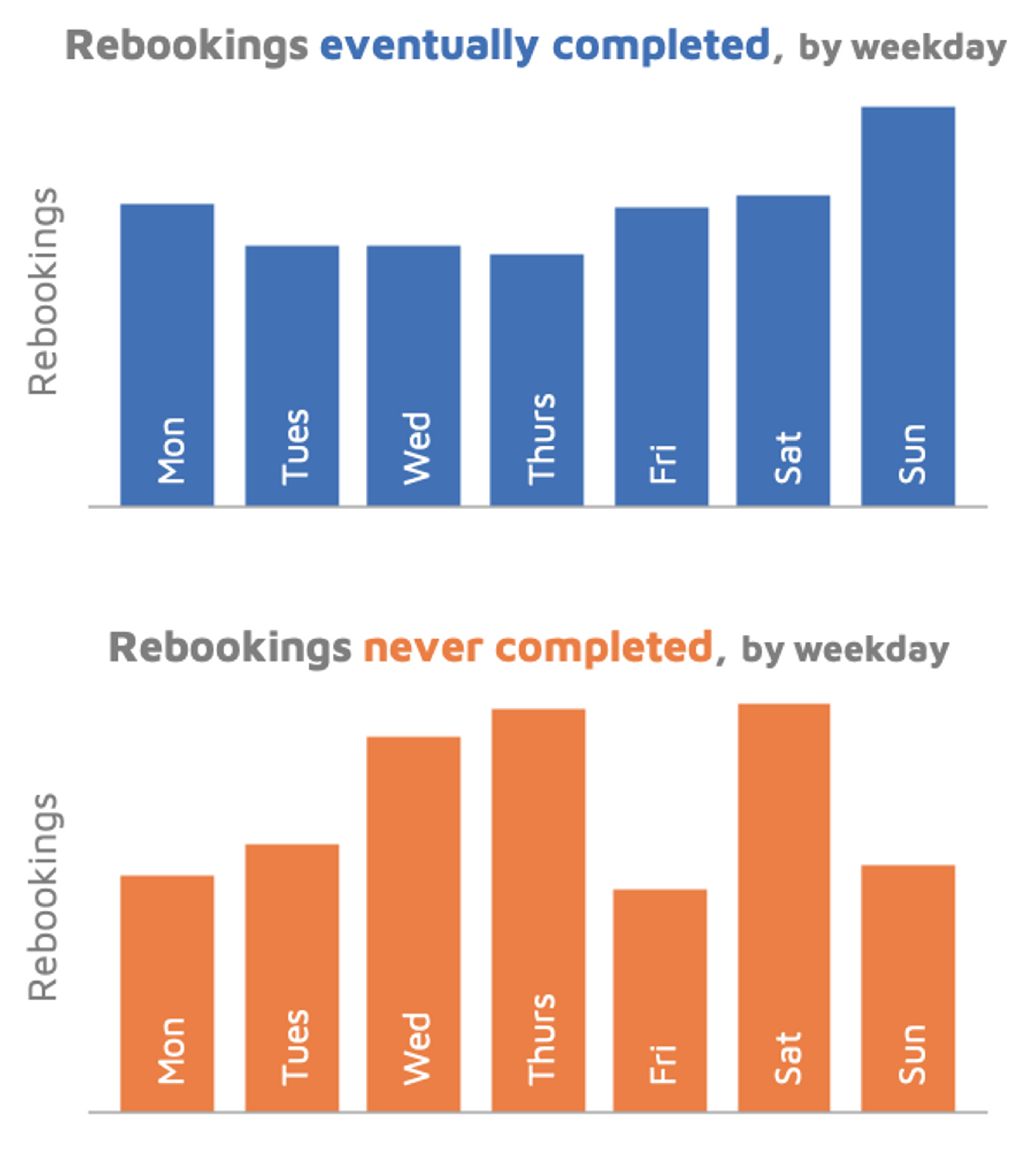
To better understand the behavioral psychology behind cancellations, we tracked individual riders through our system to see if they were rebooking a similar trip shortly after cancelling. The number of rebookings that eventually led to a completed trip increased at the weekend, whereas the number of uncompleted rebookings peaked in the middle of the week.
This reveals that weekend travelers have different ‘stickability’ compared to commuters, suggesting we should account for different travel habits in our algorithms and user interface.
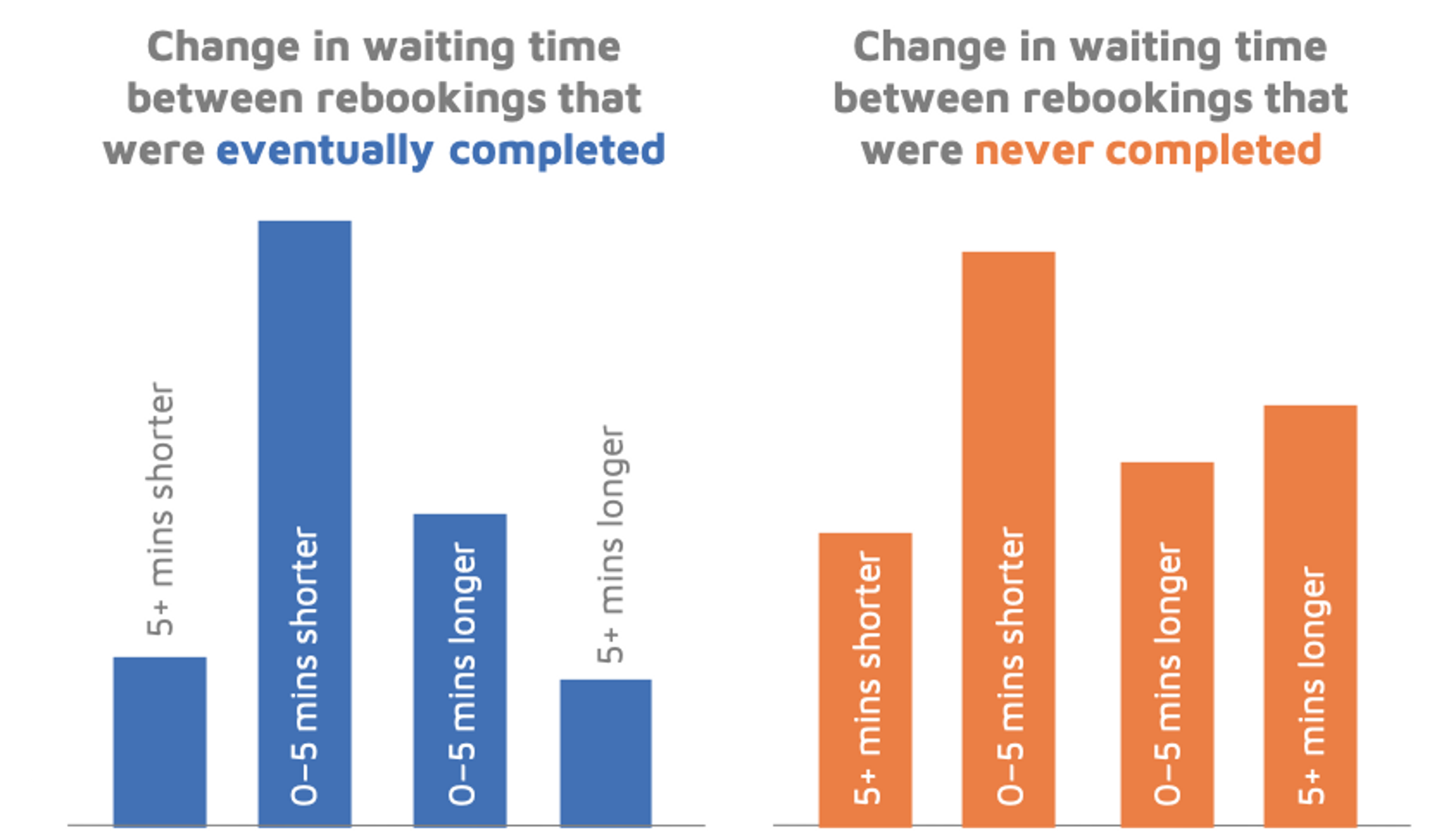
When we examine the different waiting times each rider receives before and after rebooking, we notice that not everyone games the system successfully: in fact, just under half of riders get longer waiting times after rebooking. However, riders who lose out and get significantly longer waiting times are much more likely to completely abandon their booking. How can we make sure we retain these riders more often?
One solution could be to communicate in advance with those who face longer waiting times upon rebooking. For example, we could present riders with a widget warning them of the likelihood of longer waiting times should they rebook.
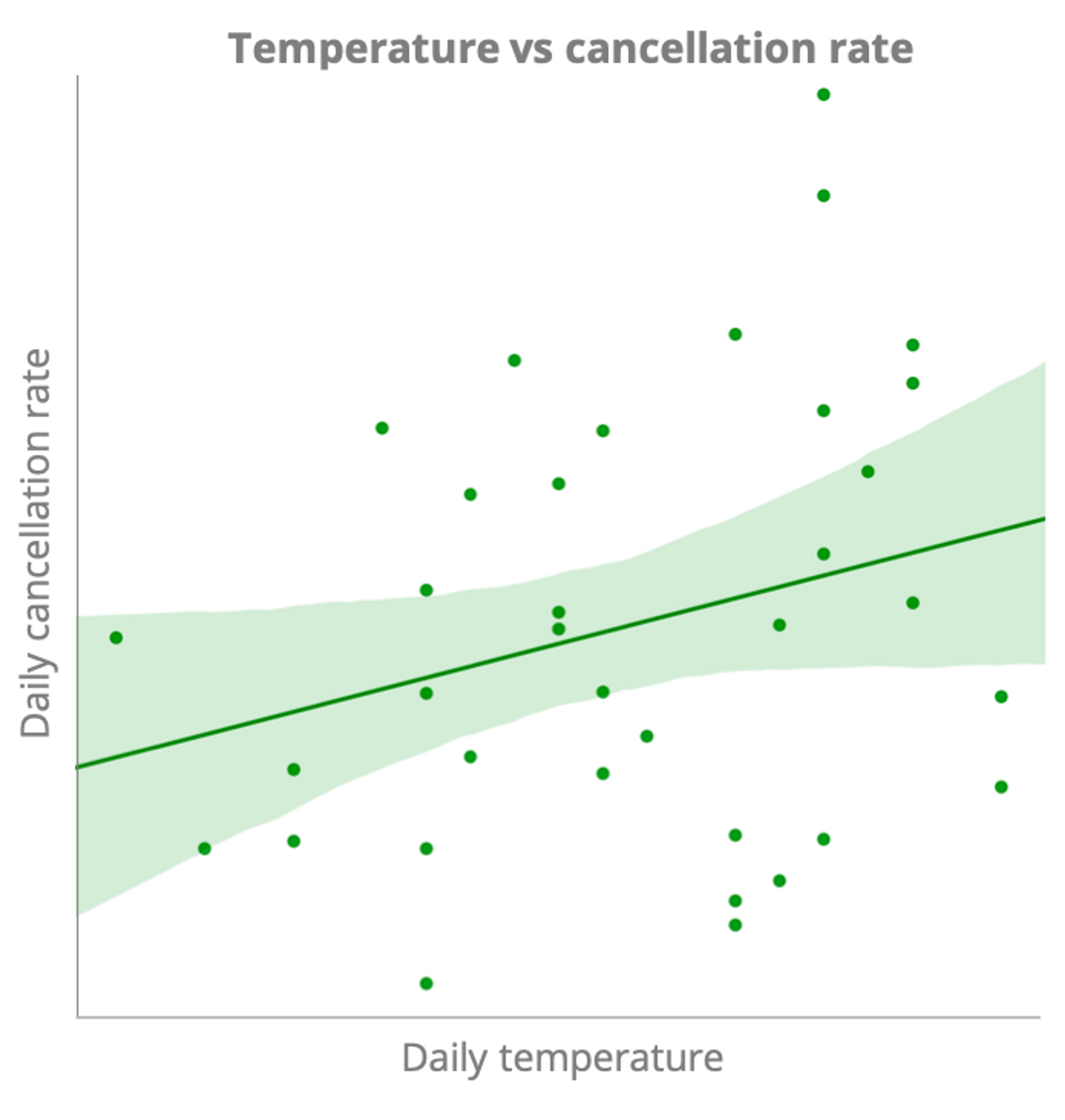
Cancellation rates could also be influenced by outside factors we have little control over, such as the weather. By plotting daily average temperature against cancellation rates, we find that there is some relation between the two: in this service at least, more people cancel when temperatures rise. This may occur because more people ride the service on hotter days, so competition is higher for rides, or people have second thoughts in nicer weather and decide to walk instead!
We can correlate cancellations with other relevant weather data, such as humidity and precipitation (rainfall or snow), but it is crucial to have high-resolution data for this. After all, individual riders don’t care for the ‘average’ weather across a day: they behave according to whether it’s hot or cold, wet or dry, at the moment they book their trip.
Predicting whether a given trip will be cancelled
Digging into past data is useful for better understanding riders’ behaviour. However, we can glean additional insights by building statistical models that can be used to predict future ridership patterns. The models consist of long equations fed with ‘predictors’, which are the aspects of a trip that might indicate whether it will be cancelled or not.
The rapid increase in computing power over recent years has allowed us to combine these complex formulae in interesting ways. Not only can we use computers to build powerful models, but the models themselves can now continue to ‘learn’ from the data they are fed with, allowing them to constantly improve. This is the ‘machine learning’ we hear so much about!
In our case, potential predictors of cancellations include the scheduled waiting times (longer waits = more frustration = more cancellations?), the number of trips recently booked by other riders (more trips = more competition for rides = more cancellations?), or the daily average temperature (warmer = happier to walk = more cancellations?).
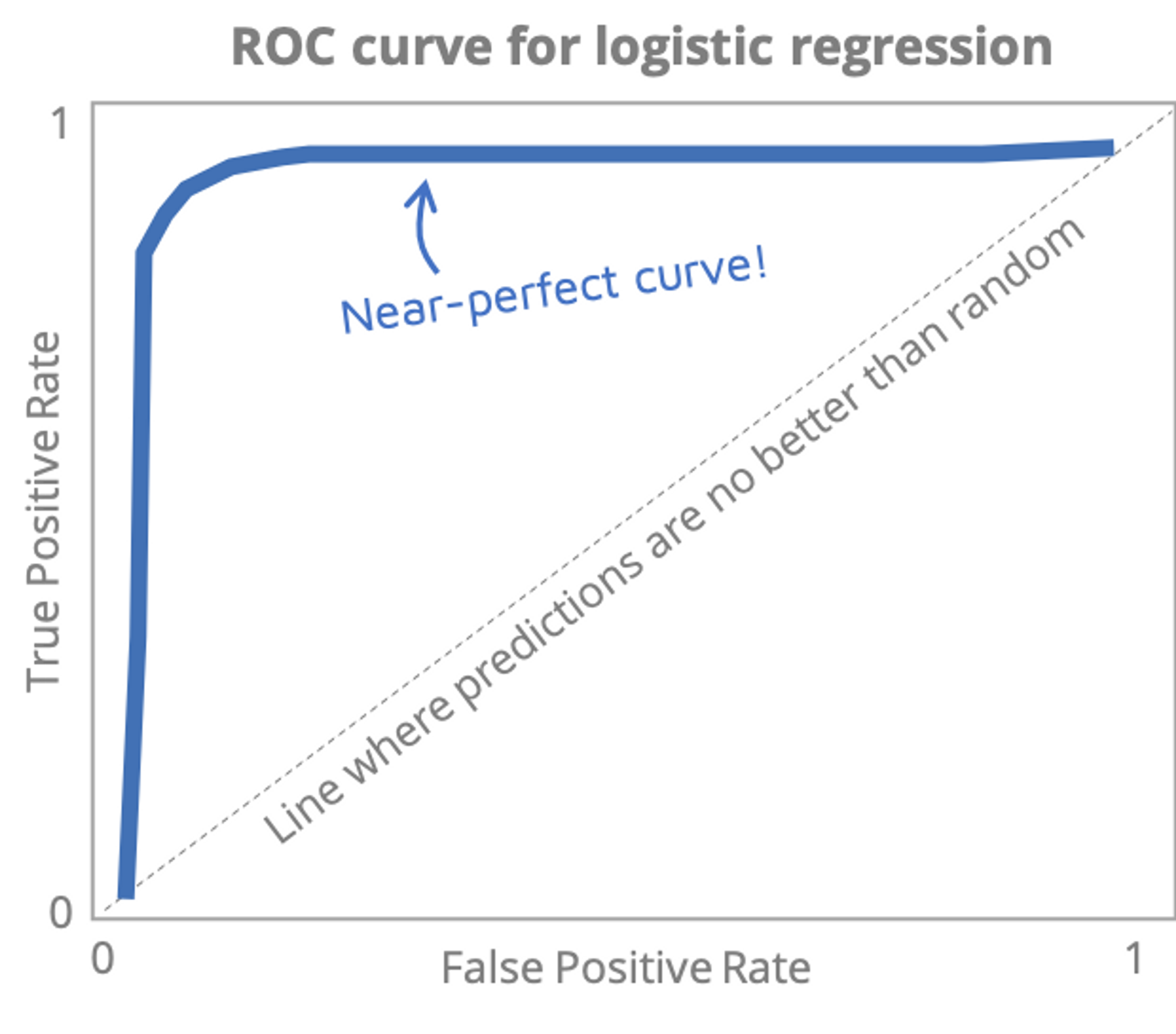
For this project, we built two machine learning models to predict whether any given trip would be cancelled. The first was a logistic regression model, known as the ‘grandfather’ of machine learning models. By training our model on one part of our data, and testing its performance on data it had never seen, it achieved an impressive accuracy of 93%. The model’s ROC curve, a popular graphical way of assessing performance, is near-perfect.
The second type of model, known as a support-vector machine (SVM), also yielded an accuracy of 93% and had a similarly excellent ROC curve.
In other words, more than nine times out of ten, our models correctly predict whether a trip will be completed or cancelled.
Predicting cancellations in advance
Although it is useful to make short-term predictions about bookings on the fly, transit organizations also need to forecast cancellations further forward in time. This allows them to adjust the number of vehicles on the road, and to make more accurate projections about ridership and fare incomes.
We used a Long-Short Term Memory neural network model (which is designed to forecast time series) to predict the number of cancellations on a daily basis:
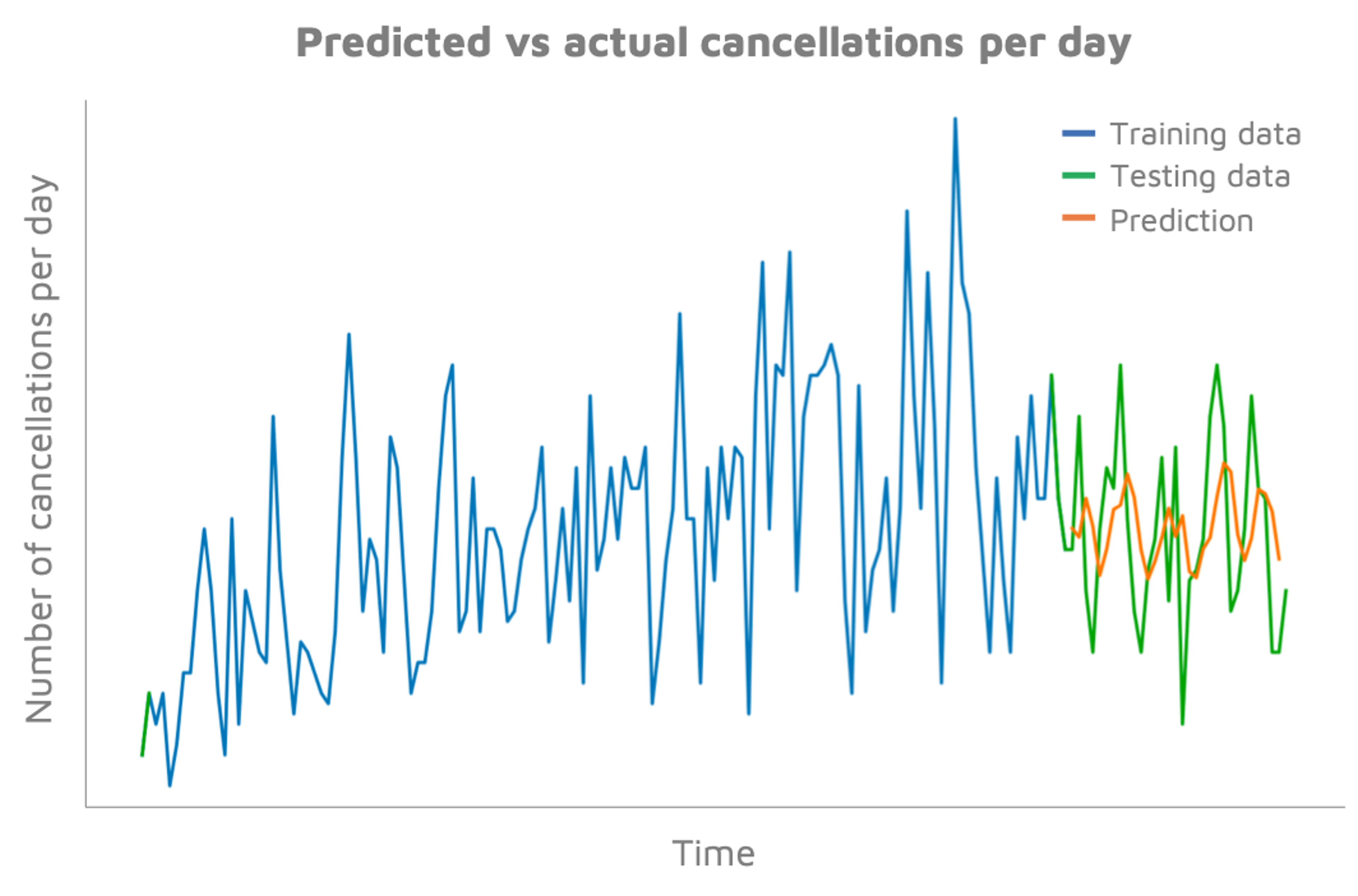
The predicted values don’t exactly match the peaks of the actual values, but the general direction seems to be roughly correct. In fact, our predicted data series has a ‘mean directional accuracy’ of 93%, meaning we can confidently predict whether cancellations will increase or decrease from one day to the next. This is simple information, but nevertheless very helpful for transit operators.
We’ve shown the central role that data science plays in uncovering patterns from Spare’s ever-growing datasets. While this blog post only featured a single service, we are testing our models using data from our services all around the world.
By continuing to collect high-quality data from vehicles and riders, and running experiments that allow us to smartly tweak our services, we can ensure on-demand transit is truly tailored to each and every one of our users.
To find out more about how Spare powers on-demand transportation of any type or size, don’t hesitate to get in touch with us at hello@sparelabs.com.